Farewell, ECS! Hello, EKS: A Kubernetes Migration Story
Table of Contents
Farewell, ECS! Hello, EKS: A Kubernetes Migration Story
Table of Contents
Saying goodbye to old systems can sound scary, but for us at EGYM, migrating from Elastic Container Service (ECS) to Elastic Kubernetes Service (EKS) was a journey of growth and excitement.
🎬 Hi there, I’m Jean!
In this blog post, I’ll share the inside scoop on our successful migration from ECS to EKS, why we did it and how, complete with the magic formula for zero downtime!
Let’s kick it off with a famous phrase in engineering:
If it ain’t broke, don’t fix it
Although this holds true in most cases, there are some situations where the costs of keeping the lights on for “what isn’t broken”, can no longer be justified.
Originally, EGYM’s entire infrastructure was hosted on a single Cloud, Google Cloud Platform (GCP), and all of our workloads were running in Google Kubernetes Engine (GKE). This held true until EGYM acquired a company, which made us embrace multi-Cloud by adding 3 ECS clusters hosted on Amazon Web Services (AWS).
While the merger itself was more or less successful from a business perspective (depending who you ask), maintaining, coaching and hiring engineers with the necessary skills to work with 2 Clouds, fundamentally different yet doing pretty much the same thing, became challenging and most importantly: costly.
With Kubernetes being Cloud-agnostic by design, we soon realized there could be potential for porting most of the core components we already used in GKE, to EKS. This fact alone made the case for moving away from ECS towards EKS much easier to sell to upper management.
Very soon, we all unanimously agreed in the SRE team that migrating to EKS was the way forward, and that we needed to evaluate its feasibility.

One of the main goals of this PoC, was to design an EKS cluster from the ground up with all the core infrastructure components that our micro-services would need to serve traffic reliably (load balancing, auto-scaling, monitoring, etc).
From all the technical choices we had to make, deciding which Load Balancer to pick was by far the most challenging. Ingress NGINX seemed like an obvious candidate for its Cloud-agnostic design, yet AWS Load Balancer Controller also caught our eye for its native integration with AWS Load Balancers.
AWS Load Balancer Controller is not a Load Balancer per se, but the Controller that provisions them. One can either provision a Network Load Balancer (NLB) using the Service annotations or an Application Load Balancer (ALB) using the Ingress annotations.
Unless explicitly configured otherwise, AWS Load Balancer Controller will provision an AWS Load Balancer per Service/Ingress resource, which can be a driver for higher costs.
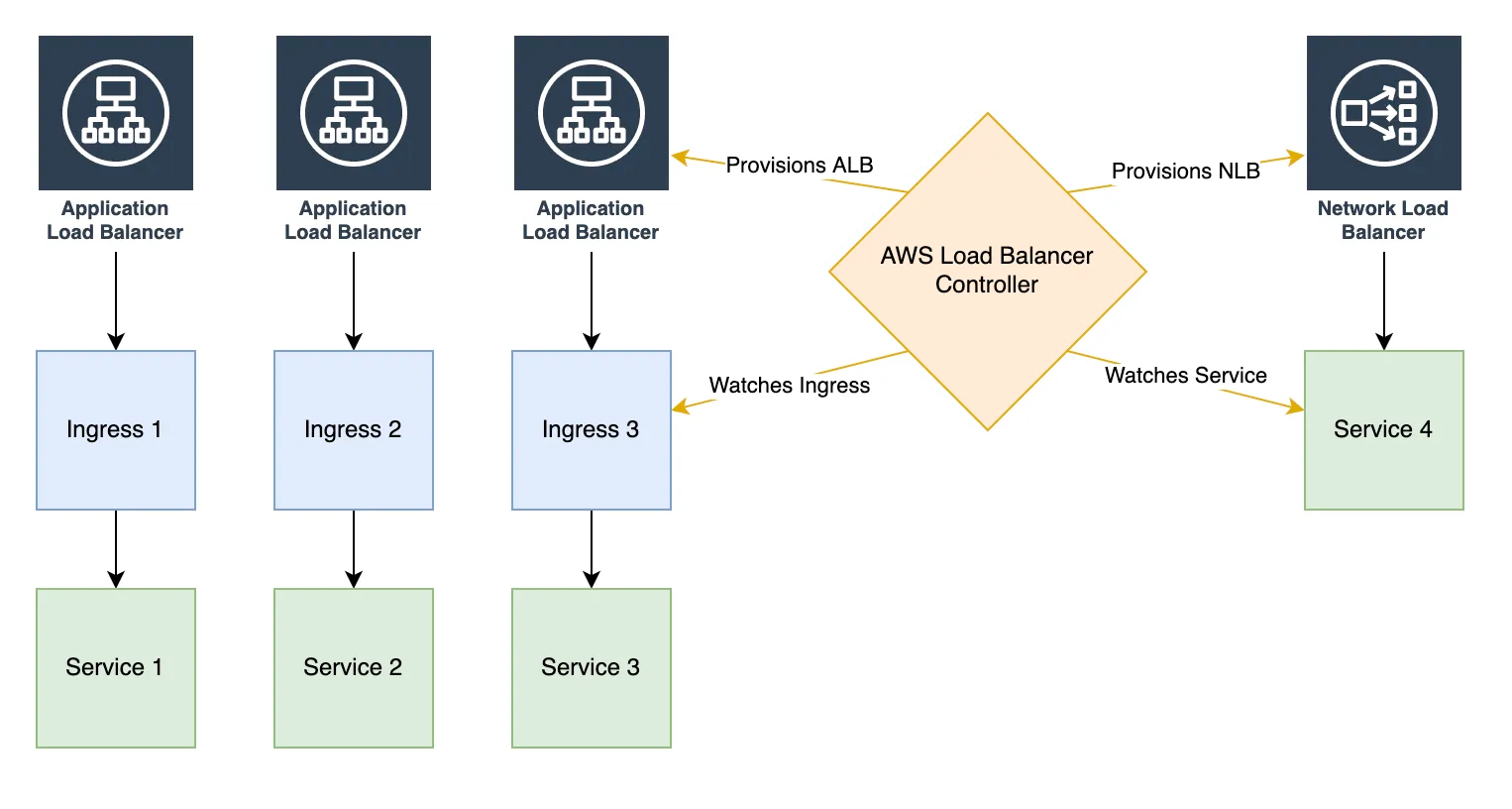
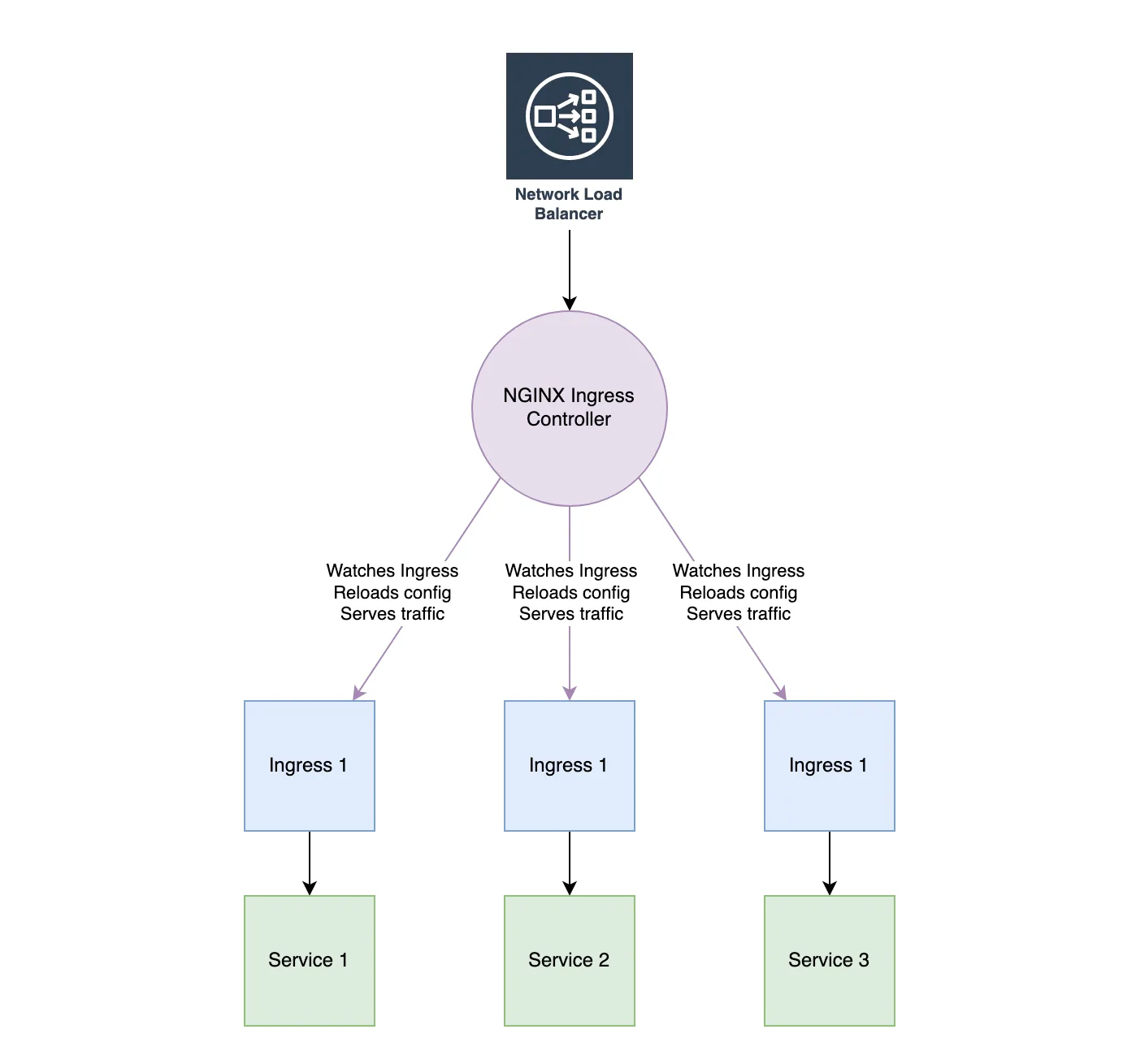
Ingress NGINX is fundamentally different in the fact that it does not only act as a Controller, but also as an L7 Load Balancer: it is responsible for both satisfying Ingress rules and load balancing HTTP traffic to the corresponding Services.
While AWS Load Balancer Controller can be used to provision both ALBs (L7 Load Balancers) and NLBs (L4 Load Balancers), Ingress NGINX needs to be itself load balanced by an L4 Load Balancer (NLB), before taking over and load balance traffic on the application layer.
As soon as our EKS clusters architecture was designed and showcased in a PoC, it was time to port the staging workloads to a new shiny EKS test cluster and make sure they function equally well in ECS and EKS.
While this part was mostly smooth sailing, here are a few issues that we faced along the way:
Once the staging workloads were successfully deployed and tested, it was time to migrate the production workloads to EKS as well!
To ensure maximum availability during the migration, we decided to run all our workloads twice: one deployment remained in the existing ECS production cluster and a new replica set was deployed in the new EKS production cluster.
This approach had the following advantages:
However, running things twice also had some drawbacks:
Eventually, all EGYM’s production workloads were deployed to EKS and tested successfully, in isolation from the services deployed in ECS.
The next step was to execute our rollout plan, which consisted of 3 phases:
While deploying EGYM’s micro-services to EKS, we took the precautionary measure of disabling asynchronous processing (PubSub, SQS/SNS, etc.) for all workloads deployed in EKS.
This way, we ensured all upstream connections were ready before we would enable event processing gradually, giving us plenty of time to observe and ensure events were processed properly.
Once asynchronous processing was enabled on all replica sets in EKS, it was finally time for the most exciting yet also treacherous part of the migration: routing user traffic.
In order to gradually pour traffic in the new EKS cluster, we took advantage of 2 routing mechanisms:
By exploiting both CloudFront Staging Distribution and Route 53 Weighted Routing routing mechanisms, we were able to gradually transfer traffic from ECS to EKS while benefiting from the incredible rollback speed of CloudFront for the first 15% of routed traffic, thus ensuring the highest availability possible.
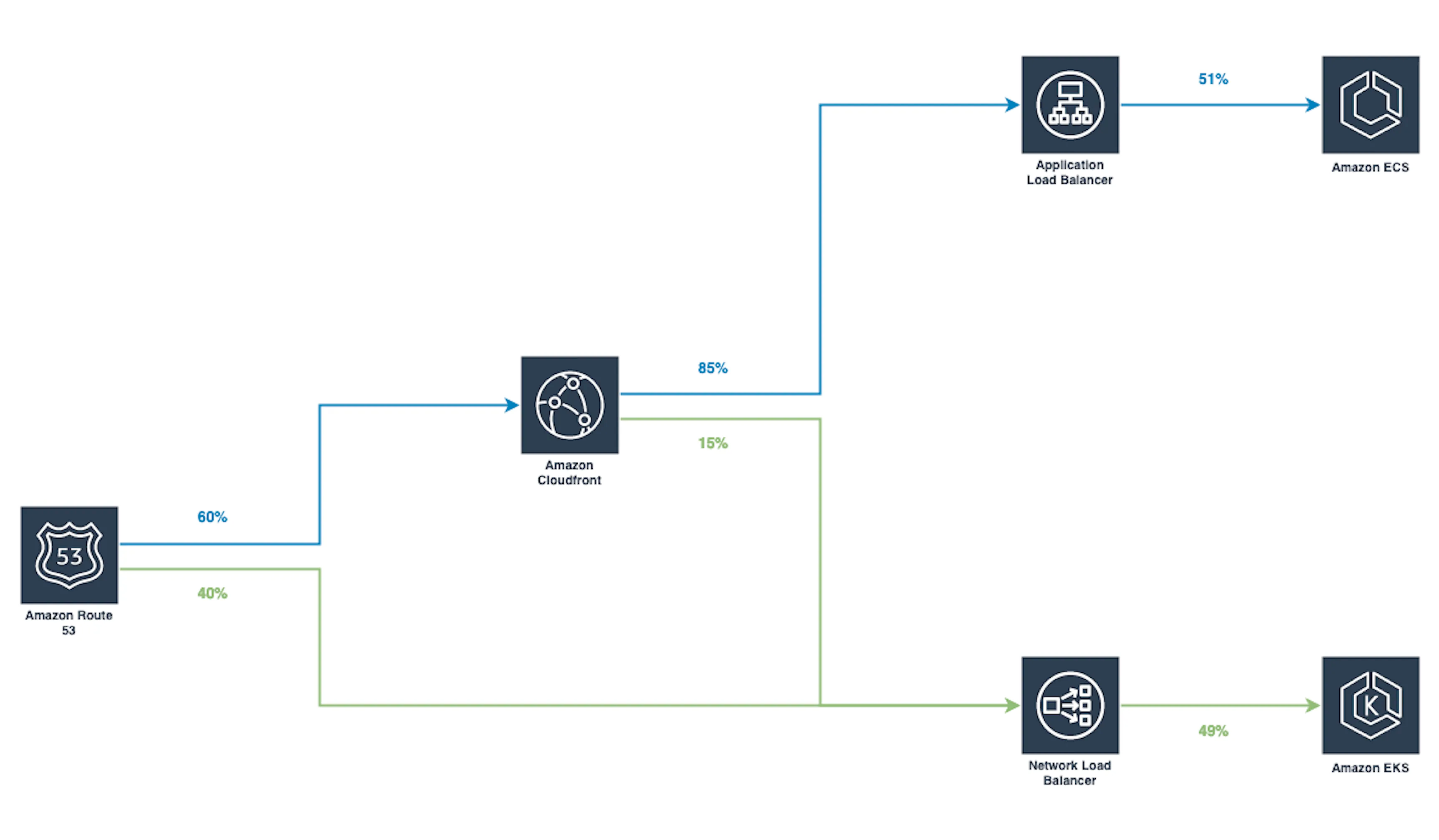
We proceeded with a gradual rollout of roughly 2 weeks, starting at 1%, followed by 5%, 10%, 15%, 25%, 35%, 50%, 65%, 80% and finally 100%.

For the first 15%, traffic routed to EKS was entirely served on CloudFront’s edges, and above the 15%, weighted routing was handled on DNS level via Route 53.
Once arrived at 80% of traffic routed to EKS, the last bump to 100% was achieved, not by routing traffic exclusively from Route 53, but by promoting the CloudFront Staging Distribution to Production Distribution instead and transfer all user traffic back to CloudFront.
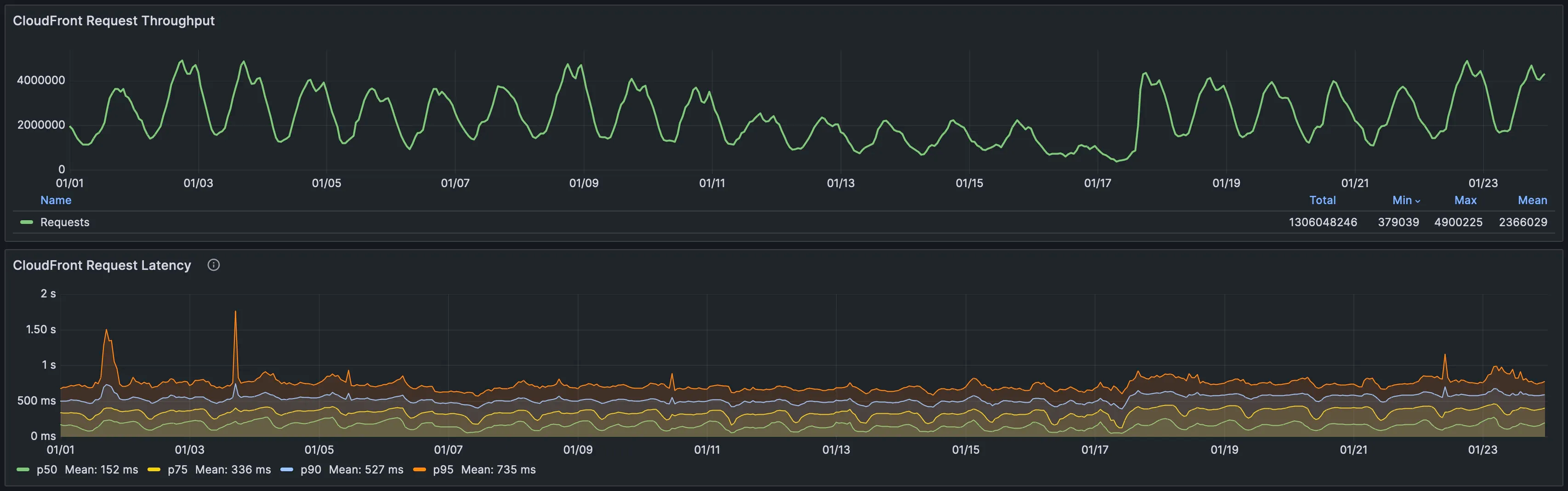
As more traffic entered the EKS cluster, we were able to cautiously observe the Horizontal Pod Autoscalers and ensure all deployments were scaling properly as the load increased.
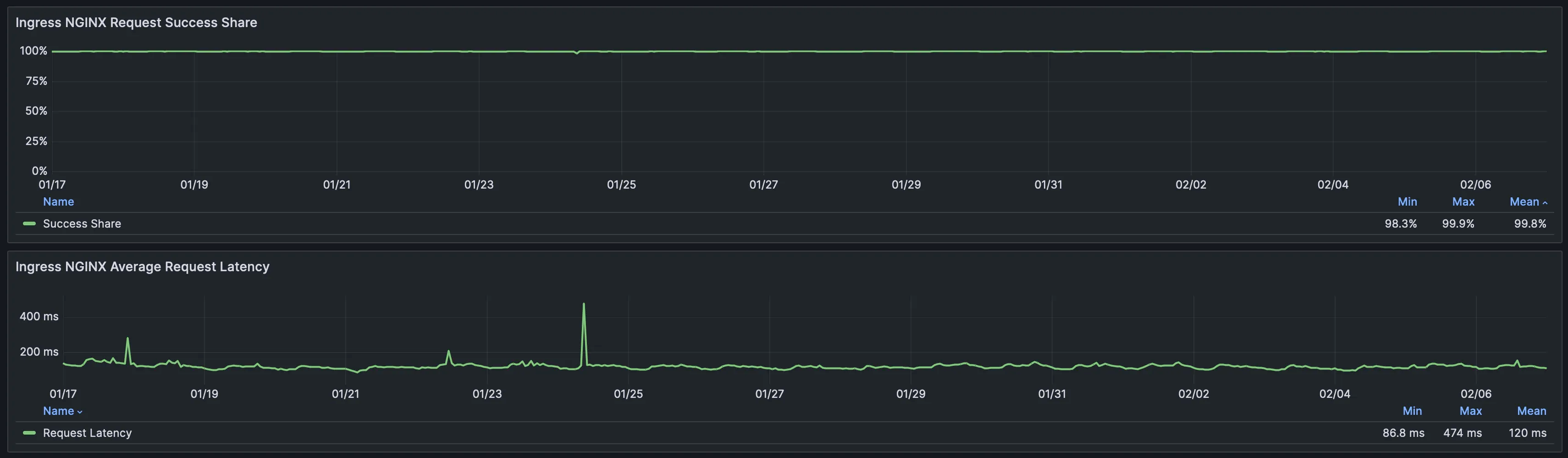
Ultimately, with the EKS cluster reporting stable and the availability of the services left intact, we were ready to proceed with the ECS scale-down.
Sunsetting workloads in ECS was the final moment of truth, leading to the fateful question: did we miss anything?
As we scaled down each service in ECS one by one, we paid special attention to asynchronous processing and event messaging until…
“The last ECS Task, a digital phoenix battling resource constraints, choked on its final heartbeat, its containerized spirit evaporating into the cloud.”
Gemini, February 2024
I would like to thank Kolawole for helping me in carrying this project to its completion, Marty for trusting me in leading the project, as well as Viktor, Serhii, Roma and Eugene for their continued support throughout the migration.
That’s it! I hope this experience was valuable to you.
If so, follow me on X, I’ll be happy to answer any of your questions and you’ll be the first one to know when a new article comes out! 👌
Bye-bye! 👋